Advantages of High Accuracy OCR Software
OCR, in most cases, is a better solution than manual data entry for capturing data from paper. However, OCR is not perfect, the errors caused by OCR result in two key problems as noted below.
High Cost of OCR Errors
OCR technology has progressed so far, that OCR is now substantially cheaper than manual data entry (except when image quality is very poor). Despite this progress, the costs of correcting OCR errors remains the biggest portion of the imaging system cost. A typical full text OCR project cost structure is illustrated below. Two thirds of the life cycle costs are to correct OCR errors.
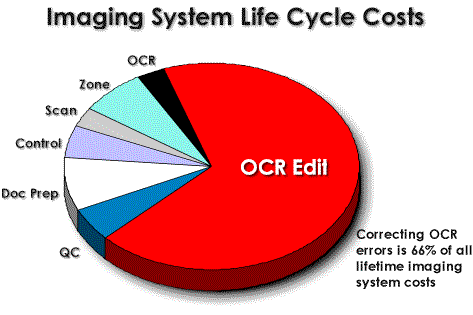
High accuracy OCR lowers the number of errors generated, which directly lowers the cost of OCR error correction. Savings are created in the project start up phase; fewer error correction workstations need to be purchased. More importantly, the larger ongoing labor costs of personnel sitting at these workstations is lowered substantially.
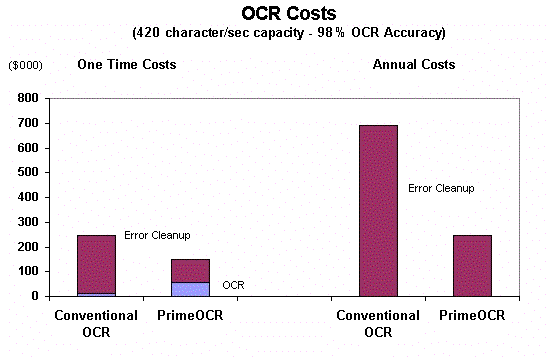
Click on the image to see a white paper that describes how these costs stack up.
Errors in Post Verification Data
Only OCR errors that are marked as "suspicious" or "low confidence" by the OCR engine are reviewed by a manual error correction person (to review all characters would be prohibitively expensive). OCR engines only mark 40-50% of their errors as suspicious. So 50-60% of OCR errors survive manual error correction and pass into the users' data repository. In some cases automated checkers can be employed such as spell check, or rule sets for "forms" applications, but at best these can correct less than 50% of the remaining errors. This means that many errors remain in the data after rule sets and manual error verification. This is a significant problem for many imaging systems, and a key reason why OCR is not used in more imaging applications.
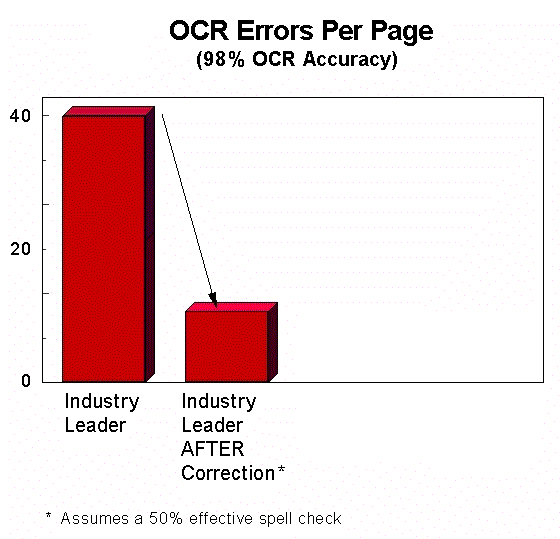
High Accuracy OCR generates better data
A high accuracy OCR engine, particularly one which is based on voting engines, has a lot more data to use to decide whether to mark a character as suspicious, and hence is much better at marking its errors as suspicious.
A high accuracy OCR engine also generates much fewer errors to start with. Therefore the net result is much fewer errors remaining in the users' data.
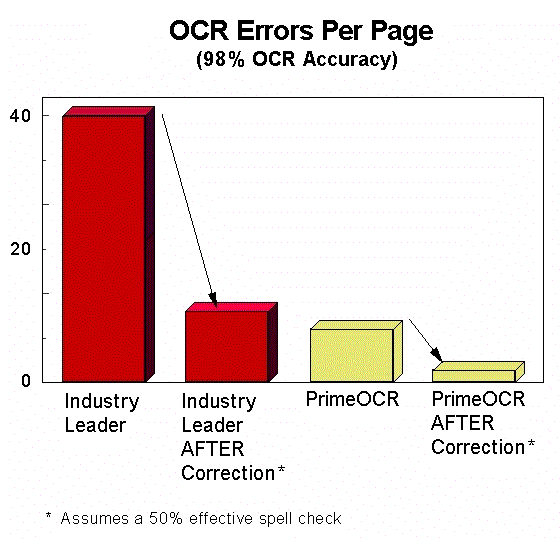
Click on the image to see a white paper that describes in more detail how high accuracy OCR offers "cleaner data".
Other links of interest:
-
Cost Justification of High Accuracy OCR (white paper)
-
Cleaner Data with High Accuracy OCR (white paper)

